在之前的lab5中,进程通过读ELF定义全局变量来标识程序的起始位置和信息,从而将程序加载到内存中,从而执行存储在磁盘上的文件读写功能。每次读入数据均从ELF文件中读入显然不现实,所以由操作系统中的文件系统来负责管理和存储可长期保存数据。alb8主要侧重于文件系统的实现,从而实现对文件和目录的一系列操作。
文件系统涉及到的内容比较多,这也是我们称之为文件系统而不是文件子系统的原因吧。
填写已有实验
本实验依赖实验1/2/3/4/5/6/7。请把你做的实验1/2/3/4/5/6/7的代码填入本实验中代码中有“LAB1”/“LAB2”/“LAB3”/“LAB4”/“LAB5”/“LAB6” /“LAB7”的注释相应部分。并确保编译通过。注意:为了能够正确执行lab8的测试应用程序,可能需对已完成的实验1/2/3/4/5/6/7的代码进行进一步改进。
1 2 3 4 5 6 7 8 9 static struct proc_struct *alloc_proc (void ) proc->filesp = NULL ; } int do_fork (uint32_t clone_flags, uintptr_t stack , struct trapframe *tf) if (copy_files(clone_flags, proc) != 0 ) { goto bad_fork_cleanup_kstack; } }
unix提出了四个文件系统抽象概念:文件(file)、目录项(dentry)、索引节点(inode)、安装点(mount point)
文件:unix文件中的内容可以理解为有序字节buffer,文件都有一个方便应用程序识别的文件名称。
目录项:目录项不是目录,而是目录的组成部分。在UNIX中目录被看作一种特定的文件,而目录项是文件路径中的一部分。如一个文件路径名是“/test/testfile”,则包含的目录项为:根目录“/”,目录“test”和文件“testfile”,这三个都是目录项。一般而言,目录项包含目录项的名字(文件名或目录名)和目录项的索引节点位置。
索引节点:UNIX将文件的相关元数据信息(如访问控制权限、大小、拥有者、创建时间、数据内容等等信息)存储在一个单独的数据结构中,该结构被称为索引节点。
安装点:在UNIX中,文件系统被安装在一个特定的文件路径位置,这个位置就是安装点。所有的已安装文件系统都作为根文件系统树中的叶子出现在系统中。
上述抽象概念形成了UNIX文件系统的逻辑数据结构,并需要通过一个具体文件系统的架构设计与实现把上述信息映射并储存到磁盘介质上。一个具体的文件系统需要在磁盘布局也实现上述抽象概念。比如文件元数据信息存储在磁盘块中的索引节点上。当文件被载如内存时,内核需要使用磁盘块中的索引点来构造内存中的索引节点。
ucore模仿了UNIX的文件系统设计,ucore的文件系统架构主要由四部分组成:
通用文件系统访问接口层:该层提供了一个从用户空间到文件系统的标准访问接口。这一层访问接口让应用程序能够通过一个简单的接口获得ucore内核的文件系统服务。
文件系统抽象层:向上提供一个一致的接口给内核其他部分(文件系统相关的系统调用实现模块和其他内核功能模块)访问。向下提供一个同样的抽象函数指针列表和数据结构屏蔽不同文件系统的实现细节。
Simple FS文件系统层:一个基于索引方式的简单文件系统实例。向上通过各种具体函数实现以对应文件系统抽象层提出的抽象函数。向下访问外设接口
外设接口层:向上提供device访问接口屏蔽不同硬件细节。向下实现访问各种具体设备驱动的接口,比如disk设备接口/串口设备接口/键盘设备接口等。
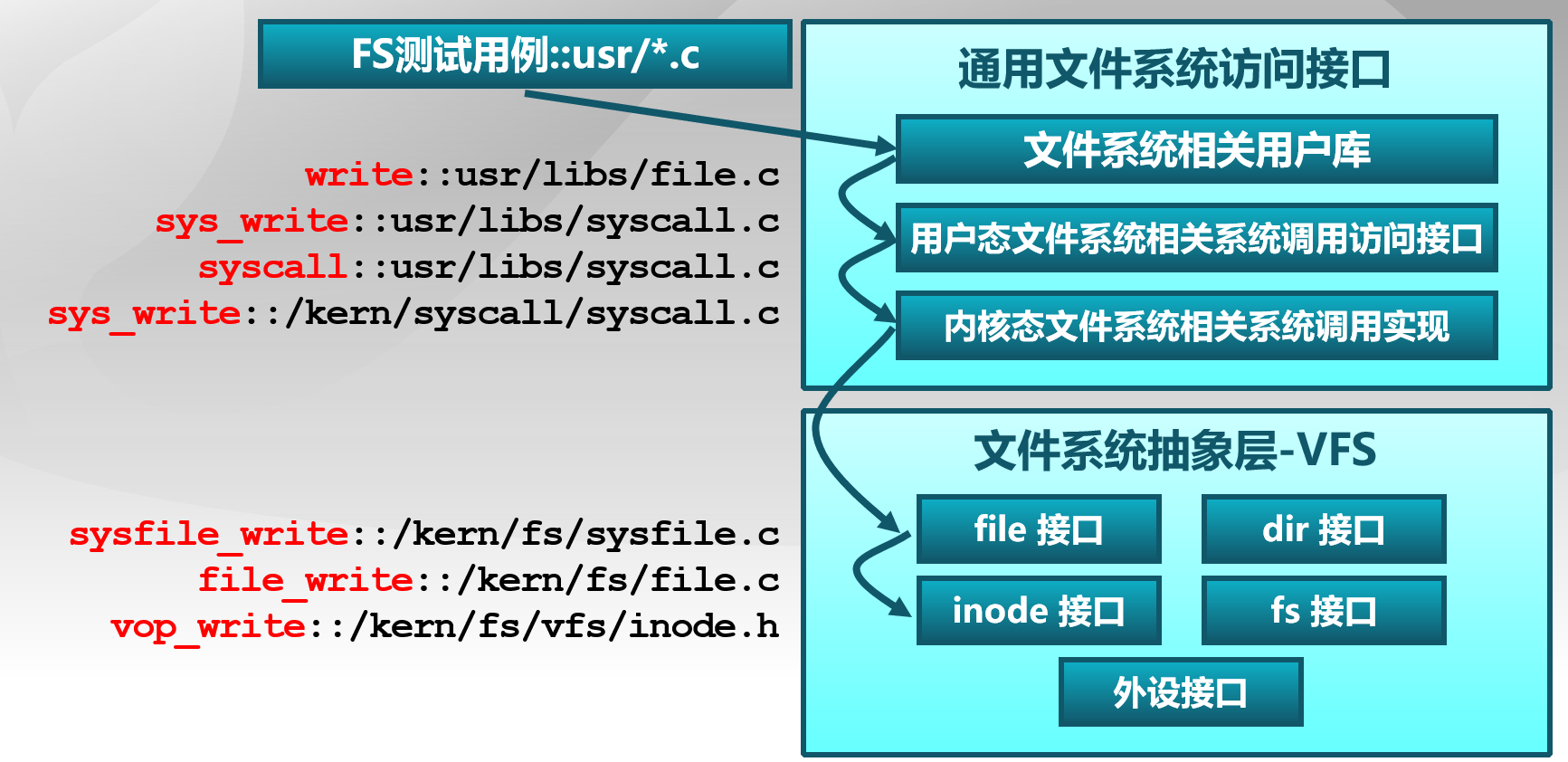
以用户态写文件函数write的整个执行过程为例,我们可以比较清晰地看到ucore文件系统架构的层次和依赖关系
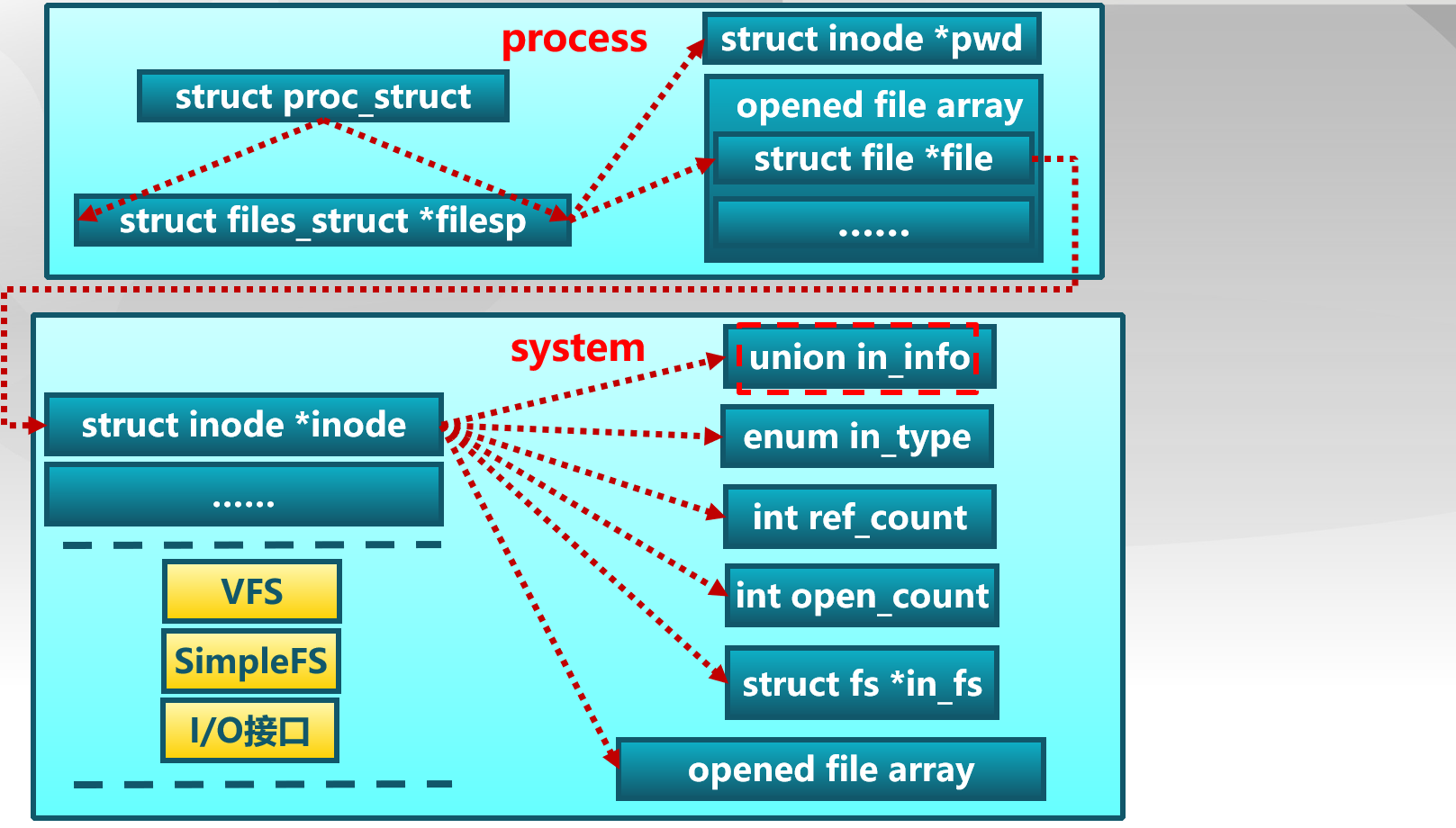
从ucore操作系统来看,ucore文件系统架构主要包含四类主要的数据结构,分别为:
超级块(SuperBlock):它主要从文件系统的全局角度描述特定文件系统的全局信息。它的作用范围是整个OS空间。
索引节点(inode):它主要从文件系统的单个文件的角度它描述了文件的各种属性和数据所在位置。它的作用范围是整个OS空间。
目录项(dentry):它主要从文件系统的文件路径的角度描述了文件路径中的特定目录。它的作用范围是整个OS空间。
文件(file),它主要从进程的角度描述了一个进程在访问文件时需要了解的文件标识,文件读写的位置,文件引用情况等信息。它的作用范围是某一具体进程。
如果一个用户进程打开了一个文件,那么在ucore中涉及的相关数据结构和关系如下所示
在kern/process/proc.h中定义的proc_struct中定义了进程访问当前文件的数据接口files_struct
1 2 3 struct proc_struct { struct files_struct *filesp ; };
files_struct数据结构定义如下:
1 2 3 4 5 6 struct files_struct { struct inode *pwd ; struct file *fd_array ; int files_count; semaphore_t files_sem; };
inode数据结构定义如下:
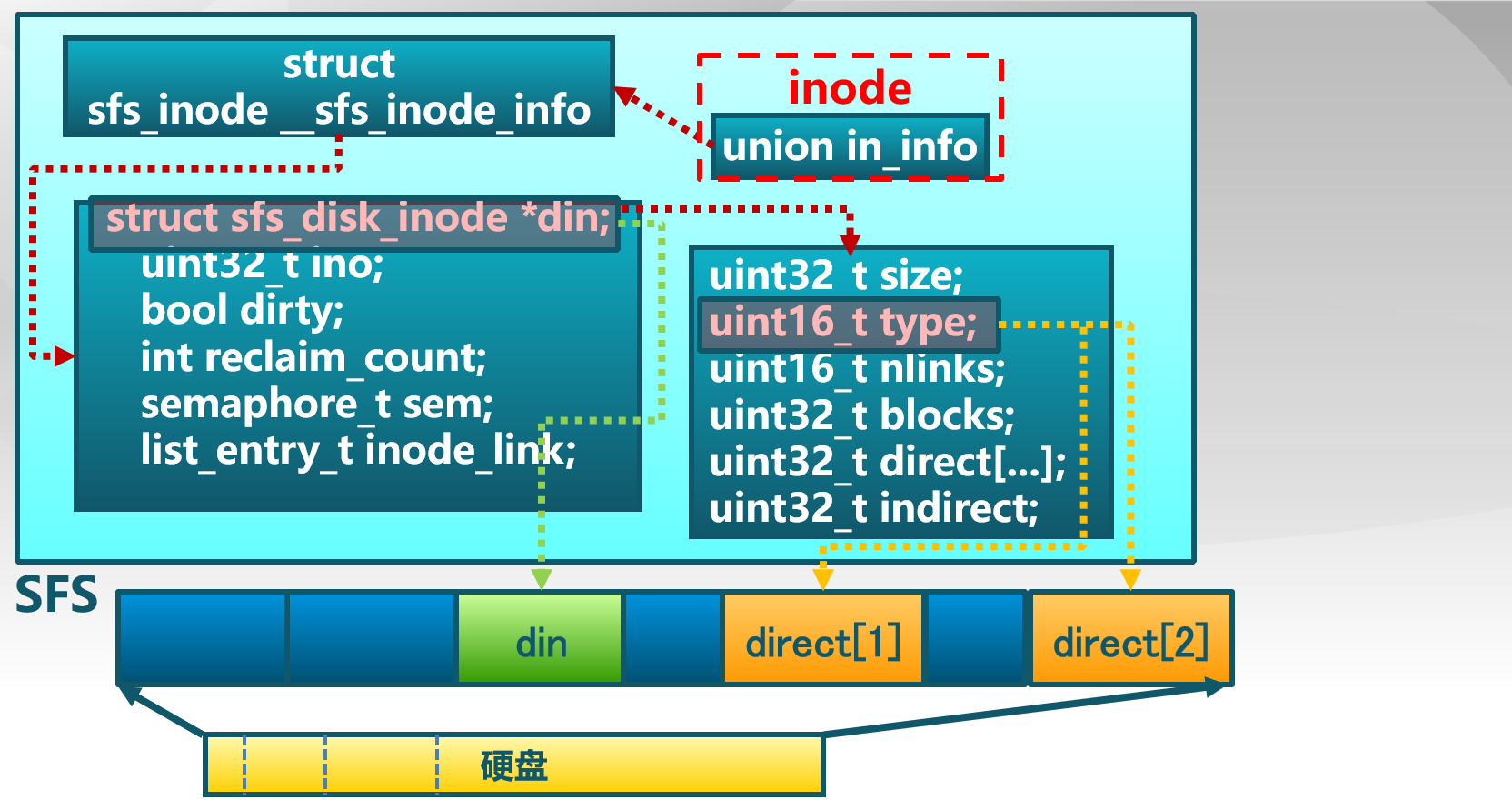
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct inode { union { struct device __device_info ; struct sfs_inode __sfs_inode_info ; } in_info; enum { inode_type_device_info = 0x1234 , inode_type_sfs_inode_info, } in_type; int ref_count; int open_count; struct fs *in_fs ; const struct inode_ops *in_ops ; };
sfs_inode数据结构定义如下:
1 2 3 4 5 6 7 8 9 10 struct sfs_inode { struct sfs_disk_inode *din ; uint32_t ino; bool dirty; int reclaim_count; semaphore_t sem; list_entry_t inode_link; list_entry_t hash_link; };
sfs_disk_inode定义如下:
1 2 3 4 5 6 7 8 9 10 11 struct sfs_disk_inode { uint32_t size; uint16_t type; uint16_t nlinks; uint32_t blocks; uint32_t direct[SFS_NDIRECT]; uint32_t indirect; };
通用文件系统访问接口 lab8中定义了一系列与文件系统有关的用户函数,首先讨论对单个文件进行操作的系统调用。
文件操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int open(const char *path, uint32_t open_flags) { return sys_open(path, open_flags); } int close(int fd) { return sys_close(fd); } int read(int fd, void *base, size_t len) { return sys_read(fd, base, len); } int write(int fd, void *base, size_t len) { return sys_write(fd, base, len); }
在文件操作方面,最基本的相关函数为open、close、read、write。在读写一个文件之前,首先调用open系统调用将文件打开。open的第一个参数指定文件的路径名,可使用绝对路径名,第二个参数指定打开的方式,可设置为O_RDONLY,O_WRONLY,O_RDWR,分别表示只读,只写,可读可写。
1 2 3 4 5 6 7 8 9 10 11 12 #define O_RDONLY 0 #define O_WRONLY 1 #define O_RDWR 2 #define O_CREAT 0x00000004 #define O_EXCL 0x00000008 #define O_TRUNC 0x00000010 #define O_APPEND 0x00000020 #define O_ACCMODE 3
读写文件内容的系统调用是read和write。read调用有三个参数:一个指定所操作的文件描述符,一个指定读取数据的存放地址,最后一个指定读多少字节。
在c语言中对应的系统调用为:
1 count = read(filehandle, buffer, nbytes);
该系统调用将实际读到的字节数返回给count变量。在正常情况下与nbytes相等,但有时可能会小一些。例如,读文件直到文件结束符的位置,从而提前结束此次读操作。若由于参数无效或者磁盘访问错误等原因此次系统调用失败,则count置为-1,write函数的参数与read函数一样。
接下来是对目录的操作。
目录操作 对于目录而言,最常用的操作是跳转到某个目录,对应的用户库函数为chdir,然后读目录的内容,即列出目录中的文件或目录名,在操作上与读文件类似,首先通过opendir打开目录,通过readdir来读取目录中的文件信息,读完后再调用closedir来关闭目录。由于在ucore中,目录为特殊的文件,所以opendir和closedir实际上是调用文件相关的open和close函数。只有readdir需要调用获取目录内容的特殊系统调用sys_getdirentry。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 DIR dir, *dirp=&dir; DIR * opendir(const char *path) { if ((dirp->fd = open(path, O_RDONLY)) < 0 ) { goto failed; } struct stat __stat , *stat = if (fstat(dirp->fd, stat) != 0 || !S_ISDIR(stat->st_mode)) { goto failed; } dirp->dirent.offset = 0 ; return dirp; failed: return NULL ; } struct dirent *readdir (DIR *dirp ) { if (sys_getdirentry(dirp->fd, &(dirp->dirent)) == 0 ) { return &(dirp->dirent); } return NULL ; } void closedir(DIR *dirp) { close(dirp->fd); }
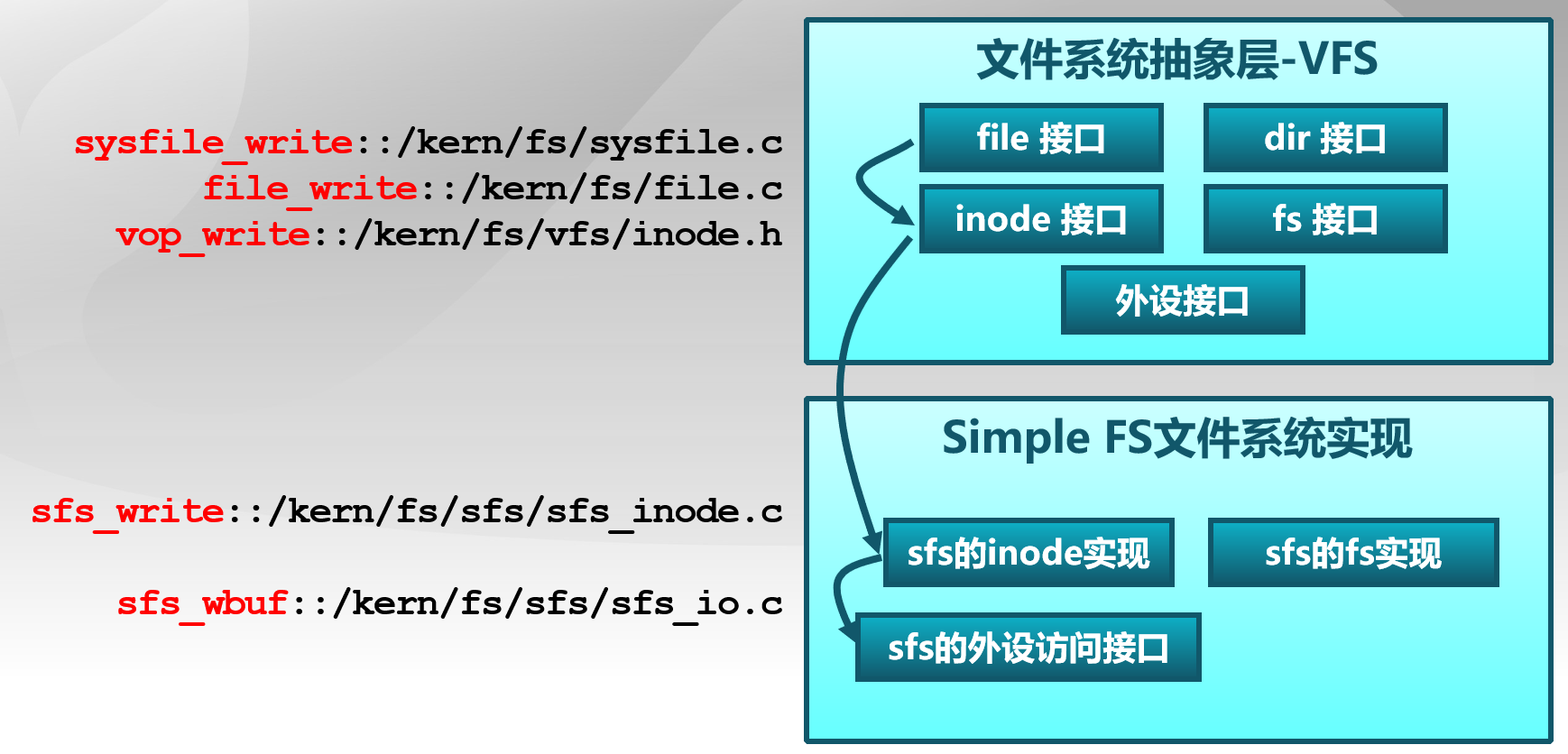
与文件相关的open、close、read、write用户库函数对应的是sys_open、sys_close、sys_read、sys_write四个系统调用接口。与目录相关的readdir用户库函数对应的是sys_getdirentry系统调用。这些系统调用函数接口将通过syscall函数来获得ucore的内核服务。在内核态时调用文件系统抽象层的文件和目录接口。
文件系统抽象层 文件系统抽象层将不同文件系统对外共性接口提取出来,与之前类似,以函数指针的形式封装,从而是通用文件系统访问层只需访问文件系统抽象层而不用关注具体实现。
文件和目录接口 文件、目录接口层定义了进程在内核中直接访问的文件相关信息,在file数据结构中定义:
1 2 3 4 5 6 7 8 9 10 11 struct file { enum { FD_NONE, FD_INIT, FD_OPENED, FD_CLOSED, } status; bool readable; bool writable; int fd; off_t pos; struct inode *node ; int open_count; };
当创建一个进程后,该进程的files_struct 会被初始化或复制当前父进程的files_struct。当用户进程打开一个文件时,将从fd_array数组中取出一个空闲的file项,将此成员变量node指针指向一个代表此文件的inode起始地址。
inode接口 inode(index node)是位于内存的节点,是文件的抽象表示,负责把不同文件系统的特定索引节点信息统一封装起来,避免了进程直接访问具体文件系统。
在inode中的成员变量inode_ops定义了一系列对inode的操作函数,具体描述如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct inode_ops { unsigned long vop_magic; int (*vop_open)(struct inode *node, uint32_t open_flags); int (*vop_close)(struct inode *node); int (*vop_read)(struct inode *node, struct iobuf *iob); int (*vop_write)(struct inode *node, struct iobuf *iob); int (*vop_fstat)(struct inode *node, struct stat *stat); int (*vop_fsync)(struct inode *node); int (*vop_namefile)(struct inode *node, struct iobuf *iob); int (*vop_getdirentry)(struct inode *node, struct iobuf *iob); int (*vop_reclaim)(struct inode *node); int (*vop_gettype)(struct inode *node, uint32_t *type_store); int (*vop_tryseek)(struct inode *node, off_t pos); int (*vop_truncate)(struct inode *node, off_t len); int (*vop_create)(struct inode *node, const char *name, bool excl, struct inode **node_store); int (*vop_lookup)(struct inode *node, char *path, struct inode **node_store); int (*vop_ioctl)(struct inode *node, int op, void *data); };
inode_ops是对常规文件、目录、设备文件所有操作的一个抽象函数表示。
SFS文件系统 ucore将所有文件视为字节流,任何内部逻辑都是专用的,由应用程序负责解释,但是ucore在物理结构上对文件加以区分。ucore目前支持以下几种类型的文件:
常规文件:文件中包括的内容信息是由应用程序输入。SFS文件系统在普通文件上不强加任何内部结构,把其文件内容信息看作为字节。
目录:包含一系列的entry,每个entry包含文件名和指向与之相关联的索引节点(index node)的指针。目录是按层次结构组织的。
链接文件:实际上一个链接文件是一个已经存在的文件的另一个可选择的文件名。
设备文件:不包含数据,但是提供了一个映射物理设备(如串口、键盘等)到一个文件名的机制。可通过设备文件访问外围设备。
管道:管道是进程间通讯的一个基础设施。管道缓存了其输入端所接受的数据,以便在管道输出端读的进程能一个先进先出的方式来接受数据。
文件系统的布局 文件系统通常保存在硬盘上,前两个磁盘分别是ucore.img和swap.img,第三个磁盘(disk 0)用于存放一个SFS文件系统。通常文件系统中磁盘的使用是以扇区为单位的,为了便于实现,SFS中以block(4K,与一页的大小相等)为基本单位。
SFS文件系统布局如下所示:
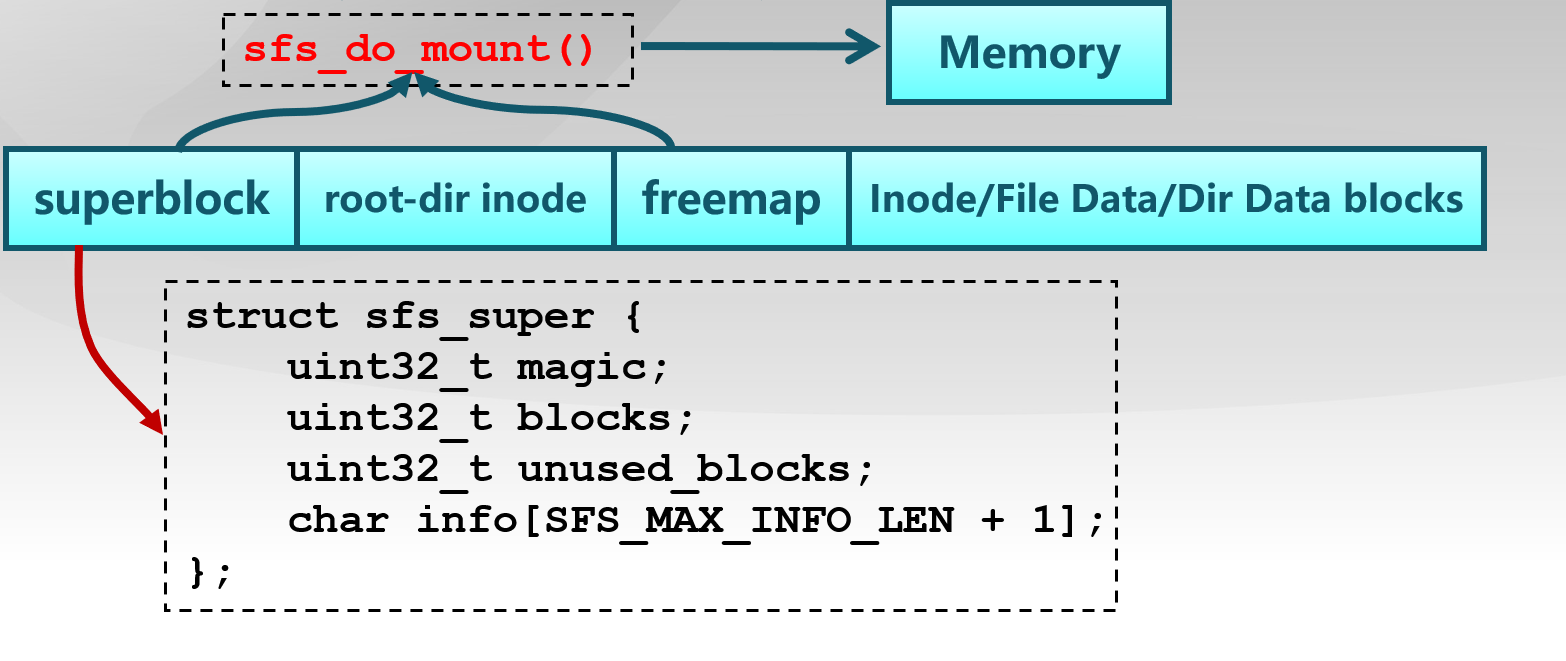
第0块(4K)是超级块,包含了关于文件系统的所有关键参数。当计算机被启动或首次接触时,超级块的内容就会被装入内存。具体描述如下:
1 2 3 4 5 6 struct sfs_super { uint32_t magic; uint32_t blocks; uint32_t unused_blocks; char info[SFS_MAX_INFO_LEN + 1 ]; };
其中magic的值在宏定义时给出,内核通过magic值来检查镜像是否为合法的SFS.img
1 #define SFS_MAGIC 0x2f8dbe2a
第1块放了root-dir的inode,用来记录根目录的相关信息。通过root-dir是sfs文件系统的根节点,通过root-dir的inode可以定位并查找到根目录下的所有文件信息。
从第2个块开始,用位图的形式来标记所有块的使用情况,每个块用1bit来标明,这个区域被称为是freemap区域。在bitmap.h中位图数据结构的定义如下:
1 2 3 4 5 struct bitmap { uint32_t nbits; uint32_t nwords; WORD_TYPE *map ; };
剩余的磁盘空间存放了所有其他目录和文件的inode信息和内容数据信息。这里每个inode都用一个完整的block来存储。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 static int sfs_do_mount(struct device *dev, struct fs **fs_store) { static_assert (SFS_BLKSIZE >= sizeof (struct sfs_super)); static_assert (SFS_BLKSIZE >= sizeof (struct sfs_disk_inode)); static_assert (SFS_BLKSIZE >= sizeof (struct sfs_disk_entry)); if (dev->d_blocksize != SFS_BLKSIZE) { return -E_NA_DEV; } struct fs *fs ; if ((fs = alloc_fs(sfs)) == NULL ) { return -E_NO_MEM; } struct sfs_fs *sfs = sfs->dev = dev; int ret = -E_NO_MEM; void *sfs_buffer; if ((sfs->sfs_buffer = sfs_buffer = kmalloc(SFS_BLKSIZE)) == NULL ) { goto failed_cleanup_fs; } if ((ret = sfs_init_read(dev, SFS_BLKN_SUPER, sfs_buffer)) != 0 ) { goto failed_cleanup_sfs_buffer; } ret = -E_INVAL; struct sfs_super *super = if (super->magic != SFS_MAGIC) { cprintf("sfs: wrong magic in superblock. (%08x should be %08x).\n" , super->magic, SFS_MAGIC); goto failed_cleanup_sfs_buffer; } if (super->blocks > dev->d_blocks) { cprintf("sfs: fs has %u blocks, device has %u blocks.\n" , super->blocks, dev->d_blocks); goto failed_cleanup_sfs_buffer; } super->info[SFS_MAX_INFO_LEN] = '\0' ; sfs->super = *super; ret = -E_NO_MEM; uint32_t i; list_entry_t *hash_list; if ((sfs->hash_list = hash_list = kmalloc(sizeof (list_entry_t ) * SFS_HLIST_SIZE)) == NULL ) { goto failed_cleanup_sfs_buffer; } for (i = 0 ; i < SFS_HLIST_SIZE; i ++) { list_init(hash_list + i); } struct bitmap *freemap ; uint32_t freemap_size_nbits = sfs_freemap_bits(super); if ((sfs->freemap = freemap = bitmap_create(freemap_size_nbits)) == NULL ) { goto failed_cleanup_hash_list; } uint32_t freemap_size_nblks = sfs_freemap_blocks(super); if ((ret = sfs_init_freemap(dev, freemap, SFS_BLKN_FREEMAP, freemap_size_nblks, sfs_buffer)) != 0 ) { goto failed_cleanup_freemap; } uint32_t blocks = sfs->super.blocks, unused_blocks = 0 ; for (i = 0 ; i < freemap_size_nbits; i ++) { if (bitmap_test(freemap, i)) { unused_blocks ++; } } assert(unused_blocks == sfs->super.unused_blocks); sfs->super_dirty = 0 ; sem_init(&(sfs->fs_sem), 1 ); sem_init(&(sfs->io_sem), 1 ); sem_init(&(sfs->mutex_sem), 1 ); list_init(&(sfs->inode_list)); cprintf("sfs: mount: '%s' (%d/%d/%d)\n" , sfs->super.info, blocks - unused_blocks, unused_blocks, blocks); fs->fs_sync = sfs_sync; fs->fs_get_root = sfs_get_root; fs->fs_unmount = sfs_unmount; fs->fs_cleanup = sfs_cleanup; *fs_store = fs; return 0 ; failed_cleanup_freemap: bitmap_destroy(freemap); failed_cleanup_hash_list: kfree(hash_list); failed_cleanup_sfs_buffer: kfree(sfs_buffer); failed_cleanup_fs: kfree(fs); return ret; }
在sfs_fs.c 文件的sfs_do_mount 函数中,加载了位于硬盘上的SFS的superblock和freemap信息,这样一来,在内存中就有了sfs文件系统的全局信息。
索引节点接口 在sfs文件系统中,需要记录文件内容的存储位置和文件名与文件内容的对应关系。sfs_disk_inode 记录了文件或目录的内容存储的索引信息。
磁盘索引节点
sfs_disk_inode 代表了一个实际位于磁盘上的文件,如果inode表示的是文件,则成员变量direct直接指向了保存文件内容数据块的索引值,indirect指向间接数据块,此数据块存放数据块索引,数据块索引才被用于存放文件内容数据。
1 2 3 4 5 6 7 8 9 10 11 struct sfs_disk_inode { uint32_t size; uint16_t type; uint16_t nlinks; uint32_t blocks; uint32_t direct[SFS_NDIRECT]; uint32_t indirect; };
默认的,ucore 里 SFS_NDIRECT 是 12,即直接索引的数据页大小为 12 * 4k = 48k;当使用一级间接数据块索引时,ucore 支持最大的文件大小为 12 * 4k + 1024 * 4k = 48k + 4m。数据索引表内,0 表示一个无效的索引,inode 里 blocks 表示该文件或者目录占用的磁盘的 block 的个数。indiret 为 0 时,表示不使用一级索引块。(因为 block 0 用来保存 super block,不可能被其他任何文件或目录使用)。
sfs_disk_entry表示一个目录中的文件或目录,与sfs_inode一样存储在硬盘,需要时读入内存。
对于普通文件,索引值指向的数据块中保存的是文件中的数据。而对于目录,索引值指向的数据块保存的是目录下所有的文件名以及对应的索引节点所在的索引块(磁盘块)所形成的数组。数据结构如下:
1 2 3 4 struct sfs_disk_entry { uint32_t ino; char name[SFS_MAX_FNAME_LEN + 1 ]; };
操作系统中,每个文件系统下的 inode 都应该分配唯一的 inode 编号。SFS 下,为了偷懒实现的简便,每个 inode 直接用所在的磁盘 block 的编号作为 inode 编号。比如,root block 的 inode 编号为 1;每个 sfs_disk_entry 数据结构中,name 表示目录下文件或文件夹的名称,ino 表示磁盘 block 编号,通过读取该 block 的数据,能够得到相应的文件或文件夹的 inode。ino 为0时,表示一个无效的 entry。
内存索引节点
1 2 3 4 5 6 7 8 9 10 struct sfs_inode { struct sfs_disk_inode *din ; uint32_t ino; bool dirty; int reclaim_count; semaphore_t sem; list_entry_t inode_link; list_entry_t hash_link; };
内存inode包含了SFS的硬盘inode信息,而且还增加了其他一些信息,这属于是便于进行是判断否改写、互斥操作、回收和快速地定位等作用。需要注意,一个内存inode是在打开一个文件后才创建的,如果关机则相关信息都会消失。而硬盘inode的内容是保存在硬盘中的,只是在进程需要时才被读入到内存中,用于访问文件或目录的具体内容数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 struct sfs_fs { struct sfs_super super ; struct device *dev ; struct bitmap *freemap ; bool super_dirty; void *sfs_buffer; semaphore_t fs_sem; semaphore_t io_sem; semaphore_t mutex_sem; list_entry_t inode_list; list_entry_t *hash_list; };
对inode操作的辅助函数如下:
sfs_bmap_load_nolock 将 sfs_inode 的第 index 个索引指向的 block 的索引值取出存到相应的指针指向的单元(ino_store),该函数只接受 index <= inode->blocks 的参数。当index == inode->blocks时,为 inode 增长一个 block。并标记 inode 为 dirty,这样可保证sfs在inode不再使用时将数据写回磁盘。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 static int sfs_bmap_load_nolock(struct sfs_fs *sfs, struct sfs_inode *sin , uint32_t index, uint32_t *ino_store) { struct sfs_disk_inode *din =sin ->din; assert(index <= din->blocks); int ret; uint32_t ino; bool create = (index == din->blocks); if ((ret = sfs_bmap_get_nolock(sfs, sin , index, create, &ino)) != 0 ) { return ret; } assert(sfs_block_inuse(sfs, ino)); if (create) { din->blocks ++; } if (ino_store != NULL ) { *ino_store = ino; } return 0 ; } static int sfs_bmap_get_nolock(struct sfs_fs *sfs, struct sfs_inode *sin , uint32_t index, bool create, uint32_t *ino_store) { struct sfs_disk_inode *din =sin ->din; int ret; uint32_t ent, ino; if (index < SFS_NDIRECT) { if ((ino = din->direct[index]) == 0 && create) { if ((ret = sfs_block_alloc(sfs, &ino)) != 0 ) { return ret; } din->direct[index] = ino; sin ->dirty = 1 ; } goto out; } index -= SFS_NDIRECT; if (index < SFS_BLK_NENTRY) { ent = din->indirect; if ((ret = sfs_bmap_get_sub_nolock(sfs, &ent, index, create, &ino)) != 0 ) { return ret; } if (ent != din->indirect) { assert(din->indirect == 0 ); din->indirect = ent; sin ->dirty = 1 ; } goto out; } else { panic ("sfs_bmap_get_nolock - index out of range" ); } out: assert(ino == 0 || sfs_block_inuse(sfs, ino)); *ino_store = ino; return 0 ; }
sfs_bmap_get_nolock 根据sfs_inode 的第 index 找到对应的磁盘数据块号。数据块索引采取多级索引方式,前12个指针直接指向数据块,此后的指针为间接数据块索引。
1 #define SFS_BLK_NENTRY (SFS_BLKSIZE / sizeof(uint32_t))
sfs_bmap_truncate_nolock释放多级数据索引表的最后一个 entry ,是 sfs_bmap_load_nolock 中,index == inode->blocks 的逆操作。当一个文件或目录被删除时,sfs 会循环调用该函数直到 inode->blocks 减为 0,释放所有的数据页。
1 2 3 4 5 6 7 8 9 10 11 12 static int sfs_bmap_truncate_nolock(struct sfs_fs *sfs, struct sfs_inode *sin ) { struct sfs_disk_inode *din =sin ->din; assert(din->blocks != 0 ); int ret; if ((ret = sfs_bmap_free_nolock(sfs, sin , din->blocks - 1 )) != 0 ) { return ret; } din->blocks --; sin ->dirty = 1 ; return 0 ; }
sfs_dirent_read_nolock:将目录的第 slot 个 entry 读取到指定的内存空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static int sfs_dirent_read_nolock(struct sfs_fs *sfs, struct sfs_inode *sin , int slot, struct sfs_disk_entry *entry) { assert(sin ->din->type == SFS_TYPE_DIR && (slot >= 0 && slot < sin ->din->blocks)); int ret; uint32_t ino; if ((ret = sfs_bmap_load_nolock(sfs, sin , slot, &ino)) != 0 ) { return ret; } assert(sfs_block_inuse(sfs, ino)); if ((ret = sfs_rbuf(sfs, entry, sizeof (struct sfs_disk_entry), ino, 0 )) != 0 ) { return ret; } entry->name[SFS_MAX_FNAME_LEN] = '\0' ; return 0 ; }
sfs_dirent_search_nolock是常用的查找函数。在目录下根据name进行查找,并且返回相应的搜索结果(文件或文件夹)的 inode 的编号(在ucore中与磁盘块编号一致),和相应的 entry 在该目录的 index 编号以及目录下的数据页是否有空闲的 entry。文件的数据页是连续的;而对于目录,数据页不是连续的,当某个 entry 删除的时候,SFS 通过设置 entry->ino 为0将该 entry 所在的 block 标记为 free,在需要添加新 entry 的时候,SFS 优先使用这些 free 的 entry,其次才会去在数据页尾追加新的 entry。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 static int sfs_dirent_search_nolock(struct sfs_fs *sfs, struct sfs_inode *sin , const char *name, uint32_t *ino_store, int *slot, int *empty_slot) { assert(strlen (name) <= SFS_MAX_FNAME_LEN); struct sfs_disk_entry *entry ; if ((entry = kmalloc(sizeof (struct sfs_disk_entry))) == NULL ) { return -E_NO_MEM; } #define set_pvalue(x, v) do { if ((x) != NULL) { *(x) = (v); } } while (0) int ret, i, nslots = sin ->din->blocks; set_pvalue(empty_slot, nslots); for (i = 0 ; i < nslots; i ++) { if ((ret = sfs_dirent_read_nolock(sfs, sin , i, entry)) != 0 ) { goto out; } if (entry->ino == 0 ) { set_pvalue(empty_slot, i); continue ; } if (strcmp (name, entry->name) == 0 ) { set_pvalue(slot, i); set_pvalue(ino_store, entry->ino); goto out; } } #undef set_pvalue ret = -E_NOENT; out: kfree(entry); return ret; } static int sfs_dirent_read_nolock(struct sfs_fs *sfs, struct sfs_inode *sin , int slot, struct sfs_disk_entry *entry) { assert(sin ->din->type == SFS_TYPE_DIR && (slot >= 0 && slot < sin ->din->blocks)); int ret; uint32_t ino; if ((ret = sfs_bmap_load_nolock(sfs, sin , slot, &ino)) != 0 ) { return ret; } assert(sfs_block_inuse(sfs, ino)); if ((ret = sfs_rbuf(sfs, entry, sizeof (struct sfs_disk_entry), ino, 0 )) != 0 ) { return ret; } entry->name[SFS_MAX_FNAME_LEN] = '\0' ; return 0 ; }
文件操作函数 1 2 3 4 5 6 7 8 9 10 11 12 13 static const struct inode_ops sfs_node_fileops = .vop_magic = VOP_MAGIC, .vop_open = sfs_openfile, .vop_close = sfs_close, .vop_read = sfs_read, .vop_write = sfs_write, .vop_fstat = sfs_fstat, .vop_fsync = sfs_fsync, .vop_reclaim = sfs_reclaim, .vop_gettype = sfs_gettype, .vop_tryseek = sfs_tryseek, .vop_truncate = sfs_truncfile, };
sfs_openfile、sfs_close、sfs_read和sfs_write分别对应用户进程发出的open、close、read、write操作。其中sfs_openfile直接返回;sfs_close需要把对文件的修改内容写回到硬盘上,这样确保硬盘上的文件内容数据是最新的;sfs_read和sfs_write函数都调用了一个函数sfs_io,并最终通过访问硬盘驱动来完成对文件内容数据的读写。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct iobuf { void *io_base; off_t io_offset; size_t io_len; size_t io_resid; }; static inline int sfs_io(struct inode *node, struct iobuf *iob, bool write) { struct sfs_fs *sfs = struct sfs_inode *sin = int ret; lock_sin(sin ); { size_t alen = iob->io_resid; ret = sfs_io_nolock(sfs, sin , iob->io_base, iob->io_offset, &alen, write); if (alen != 0 ) { iobuf_skip(iob, alen); } } unlock_sin(sin ); return ret; }
目录操作函数 1 2 3 4 5 6 7 8 9 10 11 12 static const struct inode_ops sfs_node_dirops = .vop_magic = VOP_MAGIC, .vop_open = sfs_opendir, .vop_close = sfs_close, .vop_fstat = sfs_fstat, .vop_fsync = sfs_fsync, .vop_namefile = sfs_namefile, .vop_getdirentry = sfs_getdirentry, .vop_reclaim = sfs_reclaim, .vop_gettype = sfs_gettype, .vop_lookup = sfs_lookup, };
由于目录也是一种文件,所以sfs_opendir、sys_close对应用户进程发出的open、close函数。相对于sfs_open,sfs_opendir只是完成一些open函数传递的参数判断后返回。目录的close操作与文件的close操作完全一致。由于目录的内容数据与文件的内容数据不同,所以读出目录的内容数据的函数为sfs_getdirentry,其主要工作是获取目录下的文件inode信息。
首先了解打开文件的处理流程,然后参考本实验后续的文件读写操作的过程分析,编写在sfs_inode.c中sfs_io_nolock读文件中数据的实现代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 static int sfs_io_nolock(struct sfs_fs *sfs, struct sfs_inode *sin , void *buf, off_t offset, size_t *alenp, bool write) { int ret = 0 ; size_t size, alen = 0 ; uint32_t ino; uint32_t blkno = offset / SFS_BLKSIZE; uint32_t nblks = endpos / SFS_BLKSIZE - blkno; if ((blkoff = offset % SFS_BLKSIZE) != 0 ) { size = (nblks != 0 ) ? (SFS_BLKSIZE - blkoff) : (endpos - offset); if ((ret = sfs_bmap_load_nolock(sfs, sin , blkno, &ino)) != 0 ) { goto out; } if ((ret = sfs_buf_op(sfs, buf, size, ino, blkoff)) != 0 ) { goto out; } alen += size; if (nblks == 0 ) { goto out; } buf += size, blkno ++, nblks --; } size = SFS_BLKSIZE; while (nblks != 0 ) { if ((ret = sfs_bmap_load_nolock(sfs, sin , blkno, &ino)) != 0 ) { goto out; } if ((ret = sfs_block_op(sfs, buf, ino, 1 )) != 0 ) { goto out; } alen += size, buf += size, blkno ++, nblks --; } if ((size = endpos % SFS_BLKSIZE) != 0 ) { if ((ret = sfs_bmap_load_nolock(sfs, sin , blkno, &ino)) != 0 ) { goto out; } if ((ret = sfs_buf_op(sfs, buf, size, ino, 0 )) != 0 ) { goto out; } alen += size; } out: *alenp = alen; if (offset + alen > sin ->din->size) { sin ->din->size = offset + alen; sin ->dirty = 1 ; } return ret; }
sfs_io_nolock的代码,是给定一个文件的inode以及需要读写的偏移量和大小,转换成数据块级别的读写操作。主要调用的是两个函数:
sfs_io_nolock实现的功能是根据给定的inode,文件偏移量,读写字节数从磁盘中以数据块为单位将数据从磁盘中加载到内存(buffer)中。调用的关键函数有:
sfs_bmap_load_nolock 将sfs_inode的第index个索引指向的block的索引值取出存到对应的指针单元,执行错误时返回值不为0。sfs_buf_op/sfs_block_op 传入参数为数据块对应的扇区编号,进行读写操作。
数据块的读入和读出均以块为单位进行,所以需要对边界情况进行处理。此外,用户希望的读写字节数和实际读写成功的字节数不一致,所以在每次读写操作时均会修改字节数。
实现“UNIX的PIPE机制”的概要设计方案
管道本质上就是一个操作系统内核管理的环形缓冲区,所以需要一块内存作为缓冲区,然后需要记录环形缓冲区的头部和尾部。当一个进程尝试从空管道读取数据或者向满管道写入数据的时候,操作系统内核需要将进程阻塞,所以还需要一个读取等待队列和一个写入等待队列。 缓冲区大小通常设为一页的大小4KB。
1 2 3 4 5 6 7 struct pipe { size_t head; // 缓冲区头部 size_t tail; // 缓冲区尾部 wait_queue_t read_queue; // 管道读取等待队列 wait_queue_t write_queue; // 管道写入等待队列 char* buffer; // 环形缓冲区 };
在inode中添加管道数据结构和对应的函数接口。
1 2 3 4 5 6 7 8 9 10 11 12 static const struct inode_ops dev_node_ops = .vop_magic = VOP_MAGIC, .vop_open = dev_open, .vop_close = dev_close, .vop_read = dev_read, .vop_write = dev_write, .vop_fstat = dev_fstat, .vop_ioctl = dev_ioctl, .vop_gettype = dev_gettype, .vop_tryseek = dev_tryseek, .vop_lookup = dev_lookup, };
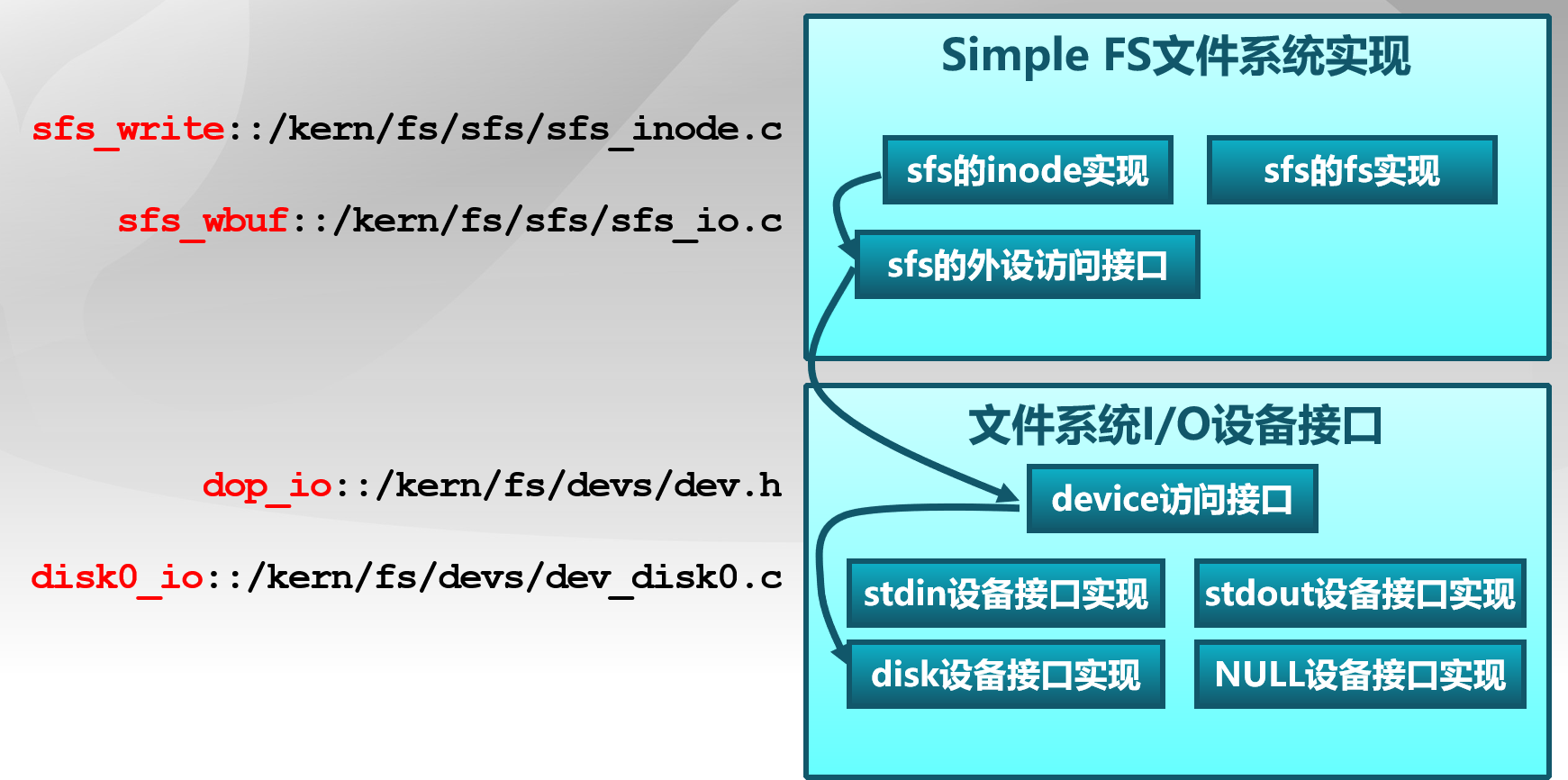
设备层文件IO层 为了统一访问设备,我们将设备同样视作文件,通过访问文件的接口来访问设备。ucore实现了stdin设备文件、stdout设备文件、disk0设备文件。stdin设备就是键盘,stdout设备就是CONSOLE(串口、并口和文本显示器),而disk0设备是承载SFS文件系统的磁盘设备。
设备接口 device数据结构具体描述如下:
1 2 3 4 5 6 7 8 struct device { size_t d_blocks; size_t d_blocksize; int (*d_open)(struct device *dev, uint32_t open_flags); int (*d_close)(struct device *dev); int (*d_io)(struct device *dev, struct iobuf *iob, bool write); int (*d_ioctl)(struct device *dev, int op, void *data); };
device数据结构用于表示块设备(比如磁盘)、字符设备(比如键盘、串口)的表示,以及对设备的基本操作。
为了将设备链接在一起,ucore定义了一个双向设备链表,通过链表可以访问所有设备文件。
1 static list_entry_t vdev_list; // device info list in vfs layer
接下来通过vfs_dev_t数据结构建立文件系统与表示一个设备文件的inode数据结构的关系。
1 2 3 4 5 6 7 typedef struct { const char *devname; struct inode *devnode ; struct fs *fs ; bool mountable; list_entry_t vdev_link; } vfs_dev_t ;
文件系统通过vfs_dev_t结构的双向链表找到device对应的inode数据结构。一个inode节点在表示设备时成员变量in_type的值是0x1234,则此 inode的成员变量in_info将成为一个device结构,这个inode就是一个设备文件。
stdout设备文件 初始化
stdout设备初始化如下:
1 2 3 kern_init-->fs_init-->dev_init-->dev_init_stdout --> dev_create_inode --> stdout_device_init --> vfs_add_dev
在dev_init_stdout中初始化stdout设备文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void dev_init_stdout(void ) { struct inode *node ; if ((node = dev_create_inode()) == NULL ) { panic("stdout: dev_create_node.\n" ); } stdout_device_init(vop_info(node, device)); int ret; if ((ret = vfs_add_dev("stdout" , node, 0 )) != 0 ) { panic("stdout: vfs_add_dev: %e.\n" , ret); } } struct inode *dev_create_inode (void ) { struct inode *node ; if ((node = alloc_inode(device)) != NULL ) { vop_init(node, &dev_node_ops, NULL ); } return node; } static void stdout_device_init(struct device *dev) { dev->d_blocks = 0 ; dev->d_blocksize = 1 ; dev->d_open = stdout_open; dev->d_close = stdout_close; dev->d_io = stdout_io; dev->d_ioctl = stdout_ioctl; }
访问操作
与一般文件基本操作函数类似,stdout设备文件同样有open、close、read、write。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static int stdout_open(struct device *dev, uint32_t open_flags) { if (open_flags != O_WRONLY) { return -E_INVAL; } return 0 ; } static int stdout_close(struct device *dev) { return 0 ; } static int stdout_ioctl(struct device *dev, int op, void *data) { return -E_INVAL; }
其中,stdout_open函数在设备打开参数不为只写时报错
stdout_io负责完成设备的写操作,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 static int stdout_io(struct device *dev, struct iobuf *iob, bool write) { if (write) { char *data = iob->io_base; for (; iob->io_resid != 0 ; iob->io_resid --) { cputchar(*data ++); } return 0 ; } return -E_INVAL; }
写入数据放在iob->io_base所指的内存区域,写入iob->io_resid次。每次写操作都是通过cputchar来完成的,通过console外设驱动来完成把数据输出到串口、并口和CGA显示器上。此外,若用户想执行读操作,则stdout_io函数直接返回错误值-E_INVAL。
stdin设备文件 stdin设备文件实际上就是键盘,为只读设备。
初始化
与stdout设备文件类似,stdin设备文件的初始化主要由stdin_device_init 完成。
1 2 3 4 5 6 7 8 9 10 11 12 static void stdin_device_init(struct device *dev) { dev->d_blocks = 0 ; dev->d_blocksize = 1 ; dev->d_open = stdin_open; dev->d_close = stdin_close; dev->d_io = stdin_io; dev->d_ioctl = stdin_ioctl; p_rpos = p_wpos = 0 ; wait_queue_init(wait_queue); }
相对于stdout的初始化过程,stdin的初始化相对复杂一些,多了一个stdin_buffer缓冲区,描述缓冲区读写位置的变量p_rpos、p_wpos以及用于等待缓冲区的等待队列wait_queue。在stdin_device_init函数的初始化中,也完成了对p_rpos、p_wpos和wait_queue的初始化。
访问操作
1 2 3 4 5 6 7 8 9 10 11 static int stdin_io(struct device *dev, struct iobuf *iob, bool write) { if (!write) { int ret; if ((ret = dev_stdin_read(iob->io_base, iob->io_resid)) > 0 ) { iob->io_resid -= ret; } return ret; } return -E_INVAL; }
若对该设备文件进行写操作则直接报错返回,若为读操作,则进一步调用dev_stdin_read完成对键盘的读入操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static int dev_stdin_read(char *buf, size_t len) { int ret = 0 ; bool intr_flag; local_intr_save(intr_flag); { for (; ret < len; ret ++, p_rpos ++) { try_again: if (p_rpos < p_wpos) { *buf ++ = stdin_buffer[p_rpos % STDIN_BUFSIZE]; } else { wait_t __wait, *wait = &__wait; wait_current_set(wait_queue, wait, WT_KBD); local_intr_restore(intr_flag); schedule(); local_intr_save(intr_flag); wait_current_del(wait_queue, wait); if (wait->wakeup_flags == WT_KBD) { goto try_again; } break ; } } } local_intr_restore(intr_flag); return ret; }
若p_rpos < p_wpos,则表示有键盘输入的新字符在stdin_buffer中,于是就从stdin_buffer中取出新字符放到iobuf指向的缓冲区中;如果p_rpos >=p_wpos,则表明没有新字符,这样调用read用户态库函数的用户进程就需要采用等待队列的睡眠操作进入睡眠状态,等待键盘输入字符的产生。
键盘输入字符后,如何唤醒等待键盘输入的用户进程呢当用户敲击键盘时,会产生键盘中断,在trap_dispatch函数中,当识别出中断是键盘中断(中断号为IRQ_OFFSET + IRQ_KBD)时,会调用dev_stdin_write函数,来把字符写入到stdin_buffer中,且会通过等待队列的唤醒操作唤醒正在等待键盘输入的用户进程。
文件系统的执行程序机制
改写proc.c中的load_icode函数和其他相关函数,实现基于文件系统的执行程序机制。执行:make qemu。如果能看看到sh用户程序的执行界面,则基本成功了。如果在sh用户界面上可以执行”ls”,”hello”等其他放置在sfs文件系统中的其他执行程序,则可以认为本实验基本成功。
load_icode分为以下几个步骤:
为当前进程建立内存空间
建立页目录表
将文件中各个段加载到内存中,同时设置虚实地址映射
设置用户堆栈并将参数放入到用户堆栈
设置当前进程的cr3,mm
为用户态设置trapframe
相比于lab7,lab8中load_icode主要变化如下:
ELF文件不再从内存读取,从文件中读入。通过调用load_icode_read函数依次将ELF header,program header以及真正的各个代码段数据段读入内存。
传入参数argc和argv,同时在用户态栈构建命令行参数,使应用程序可以接受命令行参数输入
栈空间安排如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 +------------------+ | high address | +------------------+ | argument n | +------------------+ | argument n-1 | +------------------+ | argument ... | +------------------+ | argument 1 | +------------------+ | null pointer | +------------------+ | pointer to arg n | +------------------+ | pointer to arg ..| +------------------+ | argument count | +------------------+ <- esp(stacktop) | low address | +------------------+
将命令行参数放入到栈空间中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 uint32_t len=0 ,i; for (int i=0 ;i<argc;i++){ len+=strnlen(kargv[i],EXEC_MAX_ARG_LEN+1 +1 )+1 ; } uintptr_t stacktop = USTACKTOP - (argv_size/4 +1 )*4 ; char ** uargv=(char **)(stacktop - argc * sizeof (char *)); argv_size = 0 ; for (i = 0 ; i < argc; i ++) { uargv[i] = strcpy ((char *)(stacktop + argv_size ), kargv[i]); argv_size += strnlen(kargv[i],EXEC_MAX_ARG_LEN + 1 )+1 ; } stacktop = (uintptr_t )uargv - sizeof (int ); *(int *)stacktop = argc;
二维数组压栈的时候,最后一个指针后面应该是一个空指针,表示结束,所以在栈空间内分配了4字节空间存储空指针。
实现基于UNIX硬链接和软链接机制概要设计方案
硬链接 在SFS文件系统中已经实现了nlinks数据结构,代表了指向这个inode的硬链接个数,因此只需要添加一个系统调用(例如SYS_link),该系统调用首先找到被链接文件对应的inode,然后在目标文件夹的控制块中增加一个描述符即可,二者的inode指针应该相同,同时nlinks数据结构应该相应增加
创建:
将目录项的名字设定为传入参数,目录项的inode号设置为目标文件的inode号。
目标inode的引用计数增加。
删除:
减少目标inode的引用计数。若减为0,清除目标inode及其数据块。
软链接 软链接的实现稍微复杂些,需要在inode上增加标记位确认这个文件是普通文件还是软链接文件,在进行打开文件或是保存文件的时候,操作系统需要根据软链接指向的地址再次在文件目录中进行查询,寻找或创建相应的inode,注意与硬链接不同,创建软链接的时候不涉及对nlinks的修改。如果需要创建软链接这个特殊的文件,也需要增加一个系统调用(例如SYS_symlink)在完成相应的功能。
创建:将inode的类型设置为符号链接,文件内容(数据)设置为目标路径字符串。
删除:不需要额外的操作。
打开文件流程 我们接下来分析一个用户进程在打开文件时会做哪些事情?首先假定用户进程需要打开的文件已经存在硬盘上。以user/sfs_filetest1.c为例,首先用户进程会调用在main函数中的如下语句
1 int fd1 = safe_open("/test/testfile" , O_RDWR | O_TRUNC);
若ucore可正常查找到这个文件,那么就会返回一个代表文件的文件描述符。
通用文件访问接口层
1 2 3 4 5 6 7 8 9 10 11 int sysfile_open(const char *__path, uint32_t open_flags) { int ret; char *path; if ((ret = copy_path(&path, __path)) != 0 ) { return ret; } ret = file_open(path, open_flags); kfree(path); return ret; }
首先进入通用文件访问接口层,进一步调用如下用户态函数:open->sys_open->syscall,通过系统调用进入到内核态。在内核态,通过中断处理例程跳转到sys_open内核函数,并进一步调用sysfile_open内核函数。到了这里,需要把位于用户空间的字符串/test/testfile拷贝到内核空间中的字符串path中,并进入到文件系统抽象层。
文件系统抽象层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 int file_open(char *path, uint32_t open_flags) { bool readable = 0 , writable = 0 ; switch (open_flags & O_ACCMODE) { case O_RDONLY: readable = 1 ; break ; case O_WRONLY: writable = 1 ; break ; case O_RDWR: readable = writable = 1 ; break ; default : return -E_INVAL; } int ret; struct file *file ; if ((ret = fd_array_alloc(NO_FD, &file)) != 0 ) { return ret; } struct inode *node ; if ((ret = vfs_open(path, open_flags, &node)) != 0 ) { fd_array_free(file); return ret; } file->pos = 0 ; if (open_flags & O_APPEND) { struct stat __stat , *stat = if ((ret = vop_fstat(node, stat)) != 0 ) { vfs_close(node); fd_array_free(file); return ret; } file->pos = stat->st_size; } file->node = node; file->readable = readable; file->writable = writable; fd_array_open(file); return file->fd; }
分配一个空闲的file数据结构变量file
在文件系统抽象层的处理中,首先调用的是file_open函数,为即将打开的文件分配一个file数据结构的变量。从打开文件表中依次找到状态为FD_NONE的file,将file状态改为FD_INIT,最后返回该file对应的文件描述符。此时仅仅是给当前用户进程分配了一个file数据结构的变量,还没有找到对应的文件索引节点。
找到对应索引节点
vfs_open函数先通过vfs_lookup找到path对应文件的inode;之后调用vop_open函数打开文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 int vfs_open(char *path, uint32_t open_flags, struct inode **node_store) { bool can_write = 0 ; switch (open_flags & O_ACCMODE) { case O_RDONLY: break ; case O_WRONLY: case O_RDWR: can_write = 1 ; break ; default : return -E_INVAL; } if (open_flags & O_TRUNC) { if (!can_write) { return -E_INVAL; } } int ret; struct inode *node ; bool excl = (open_flags & O_EXCL) != 0 ; bool create = (open_flags & O_CREAT) != 0 ; ret = vfs_lookup(path, &node); if (ret != 0 ) { if (ret == -16 && (create)) { char *name; struct inode *dir ; if ((ret = vfs_lookup_parent(path, &dir, &name)) != 0 ) { return ret; } ret = vop_create(dir, name, excl, &node); } else return ret; } else if (excl && create) { return -E_EXISTS; } assert(node != NULL ); if ((ret = vop_open(node, open_flags)) != 0 ) { vop_ref_dec(node); return ret; } vop_open_inc(node); if (open_flags & O_TRUNC || create) { if ((ret = vop_truncate(node, 0 )) != 0 ) { vop_open_dec(node); vop_ref_dec(node); return ret; } } *node_store = node; return 0 ; }
vfs_lookup为针对目录的操作函数。首先调用get_device函数查找文件设备的根目录,并选择开始查找的相对inode。例如,确定C:\Users\abc的文件设备为c盘。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int vfs_lookup(char *path, struct inode **node_store) { int ret; struct inode *node ; if ((ret = get_device(path, &path, &node)) != 0 ) { return ret; } if (*path != '\0' ) { ret = vop_lookup(node, path, node_store); vop_ref_dec(node); return ret; } *node_store = node; return 0 ; }
根据冒号和反斜杠出现的首位置判断,分为以下几种情况
冒号不在反斜杠之前,同时反斜杠不在首部或不存在,为相对路径或仅仅只是一个文件名。 以路径为子路径,从当前目录开始查找。
冒号存在于反斜杠之前,为device:path形式,从路径名称中取得根目录。
/path 为相对于bootfs的路径,调用vfs_get_bootfs 取得bootfs_node。bootfs_node在init_main函数中设置为disk0。:path 为相对于当前文件系统的路径
通过调用vop_lookup函数来查找到根目录下/对应文件sfs_filetest1的索引节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 static int get_device(char *path, char **subpath, struct inode **node_store) { int i, slash = -1 , colon = -1 ; for (i = 0 ; path[i] != '\0' ; i ++) { if (path[i] == ':' ) { colon = i; break ; } if (path[i] == '/' ) { slash = i; break ; } } if (colon < 0 && slash != 0 ) { *subpath = path; return vfs_get_curdir(node_store); } if (colon > 0 ) { path[colon] = '\0' ; while (path[++ colon] == '/' ); *subpath = path + colon; return vfs_get_root(path, node_store); } int ret; if (*path == '/' ) { if ((ret = vfs_get_bootfs(node_store)) != 0 ) { return ret; } } else { assert(*path == ':' ); struct inode *node ; if ((ret = vfs_get_curdir(&node)) != 0 ) { return ret; } assert(node->in_fs != NULL ); *node_store = fsop_get_root(node->in_fs); vop_ref_dec(node); } while (*(++ path) == '/' ); *subpath = path; return 0 ; }
此后将返回到file_open函数中,通过执行语句file->node=node,将查找到的inode赋值给文件对应的inode然后返回fd。经过重重回退,通过系统调用返回,用户态的syscall->sys_open->open->safe_open等用户函数的层层函数返回,最终把把fd赋值给fd1。
SFS层文件系统层
sfs_inode.c中的sfs_node_dirops变量定义了.vop_lookup = sfs_lookup,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static int sfs_lookup(struct inode *node, char *path, struct inode **node_store) { struct sfs_fs *sfs = assert(*path != '\0' && *path != '/' ); vop_ref_inc(node); struct sfs_inode *sin = if (sin ->din->type != SFS_TYPE_DIR) { vop_ref_dec(node); return -E_NOTDIR; } struct inode *subnode ; int ret = sfs_lookup_once(sfs, sin , path, &subnode, NULL ); vop_ref_dec(node); if (ret != 0 ) { return ret; } *node_store = subnode; return 0 ; } static int sfs_lookup_once(struct sfs_fs *sfs, struct sfs_inode *sin , const char *name, struct inode **node_store, int *slot) { int ret; uint32_t ino; lock_sin(sin ); { ret = sfs_dirent_search_nolock(sfs, sin , name, &ino, slot, NULL ); } unlock_sin(sin ); if (ret == 0 ) { ret = sfs_load_inode(sfs, node_store, ino); } return ret; }
sfs_lookup有三个参数:node,path,node_store。其中node是根目录/所对应的inode节点;path是文件testfile的绝对路径/test/testfile,而node_store是经过查找获得的testfile所对应的inode节点。
sfs_lookup函数以/为分割符,从左至右逐一分解path获得各个子目录和最终文件对应的inode节点。在本例中是分解出test子目录,并调用sfs_lookup_once函数获得test子目录对应的inode节点subnode,然后循环进一步调用sfs_lookup_once查找以test子目录下的文件testfile1所对应的inode节点。当无法分解path后,就意味着顺利找到了testfile1对应的inode节点。
sfs_lookup_once将调用sfs_dirent_search_nolock函数来查找与路径名匹配的目录项,如果找到目录项,则根据目录项中记录的inode所处的数据块索引值找到路径名对应的SFS磁盘inode,并读入SFS磁盘inode对应的内容,创建SFS内存inode。
读文件流程 读文件其实就是读出目录中的目录项,首先假定文件在磁盘上且已经打开。用户进程有如下语句:
即读取fd对应文件,读取长度为len,存入data中。
通用文件访问接口层
首先进入通用文件访问接口层,进一步调用如下用户态函数:open->sys_open->syscall,通过系统调用进入到内核态。在内核态,通过中断处理例程跳转到sys_read内核函数,并进一步调用sysfile_read内核函数,进入到文件系统抽象层完成进一步读文件的操作。
文件系统抽象层的处理流程
检查错误,即检查读取长度是否为0和文件是否可读。
分配buffer空间,即调用kmalloc函数分配4096字节的buffer空间。
读文件过程
[1] 实际读文件
循环读取文件,每次读取buffer大小。每次循环中,先检查剩余部分大小,若其小于4096字节,则只读取剩余部分的大小。然后调用file_read函数(详细分析见后)将文件内容读取到buffer中,alen为实际大小。调用copy_to_user函数将读到的内容拷贝到用户的内存空间中,调整各变量以进行下一次循环读取,直至指定长度读取完成。最后函数调用层层返回至用户程序,用户程序收到了读到的文件内容。
[2] file_read函数
这个函数是读文件的核心函数。函数有4个参数,fd是文件描述符,base是缓存的基地址,len是要读取的长度,copied_store存放实际读取的长度。函数首先调用fd2file函数找到对应的file结构,并检查是否可读。调用filemap_acquire函数使打开这个文件的计数加1。调用vop_read函数将文件内容读到iob中(详细分析见后)。调整文件指针偏移量pos的值,使其向后移动实际读到的字节数iobuf_used(iob)。最后调用filemap_release函数使打开这个文件的计数减1,若打开计数为0,则释放file。
SFS文件系统层
在sfs_inode.c中sfs_node_fileops变量定义了.vop_read = sfs_read。
sfs_read函数调用sfs_io函数。它有三个参数,node是对应文件的inode,iob是缓存,write表示是读还是写的布尔值(0表示读,1表示写)。函数先找到inode对应sfs和sin,然后调用sfs_io_nolock函数进行读取文件操作,最后调用iobuf_skip函数调整iobuf的指针。
在sfs_io_nolock函数中,先计算一些辅助变量,并处理一些特殊情况(比如越界),然后有sfs_buf_op = sfs_rbuf,sfs_block_op = sfs_rblock,设置读取的函数操作。接着进行实际操作,先处理起始的没有对齐到块的部分,再以块为单位循环处理中间的部分,最后处理末尾剩余的部分。每部分中都调用sfs_bmap_load_nolock函数得到blkno对应的inode编号,并调用sfs_rbuf或sfs_rblock函数读取数据(中间部分调用sfs_rblock,起始和末尾部分调用sfs_rbuf),调整相关变量。完成后如果offset + alen > din->fileinfo.size(写文件时会出现这种情况,读文件时不会出现这种情况,alen为实际读写的长度),则调整文件大小为offset + alen并设置dirty变量。
sfs_bmap_load_nolock函数将对应sfs_inode的第index个索引指向的block的索引值取出存到相应的指针指向的单元(ino_store)。它调用sfs_bmap_get_nolock来完成相应的操作。sfs_rbuf和sfs_rblock函数最终都调用sfs_rwblock_nolock函数完成操作,而sfs_rwblock_nolock函数调用dop_io->disk0_io->disk0_read_blks_nolock->ide_read_secs完成对磁盘的操作。