ucore lab3
ucore lab2通过段页式机制将虚拟内存映射到物理内存,并具体实现了物理内存管理空间中的连续内存分配算法。ucore lab3将实现非连续内存分配中的虚拟内存,借助之前的页表机制和中断异常机制,通过缺页异常的处理来衔接虚拟内存和物理内存之间的差异。与前者差异主要区别在于如何在磁盘交换区缓存页,从而提供比实际物理内存更大的虚拟内存空间。
lab2没有从一般应用程序对内存需求考虑,缺少相关的数据结构和操作来体现一般应用程序对虚拟内存的需求。ucore通过page fault异常处理来简洁完成虚拟内存和物理内存二者之间的衔接。故引入以下两个数据结构,描述ucore模拟应用程序所需的合法内存空间。当访问内存产生page fault异常时,根据访问内存的读写方式和具体的虚拟内存地址,判断是否在vma_struct所描述的合法地址空间范围内,如果在,则可根据具体情况请求调页/页换入换出处理,如果不在则报错。
1 | //mm结构体描述一个进程的虚拟地址空间,为进程pcb的成员变量 |
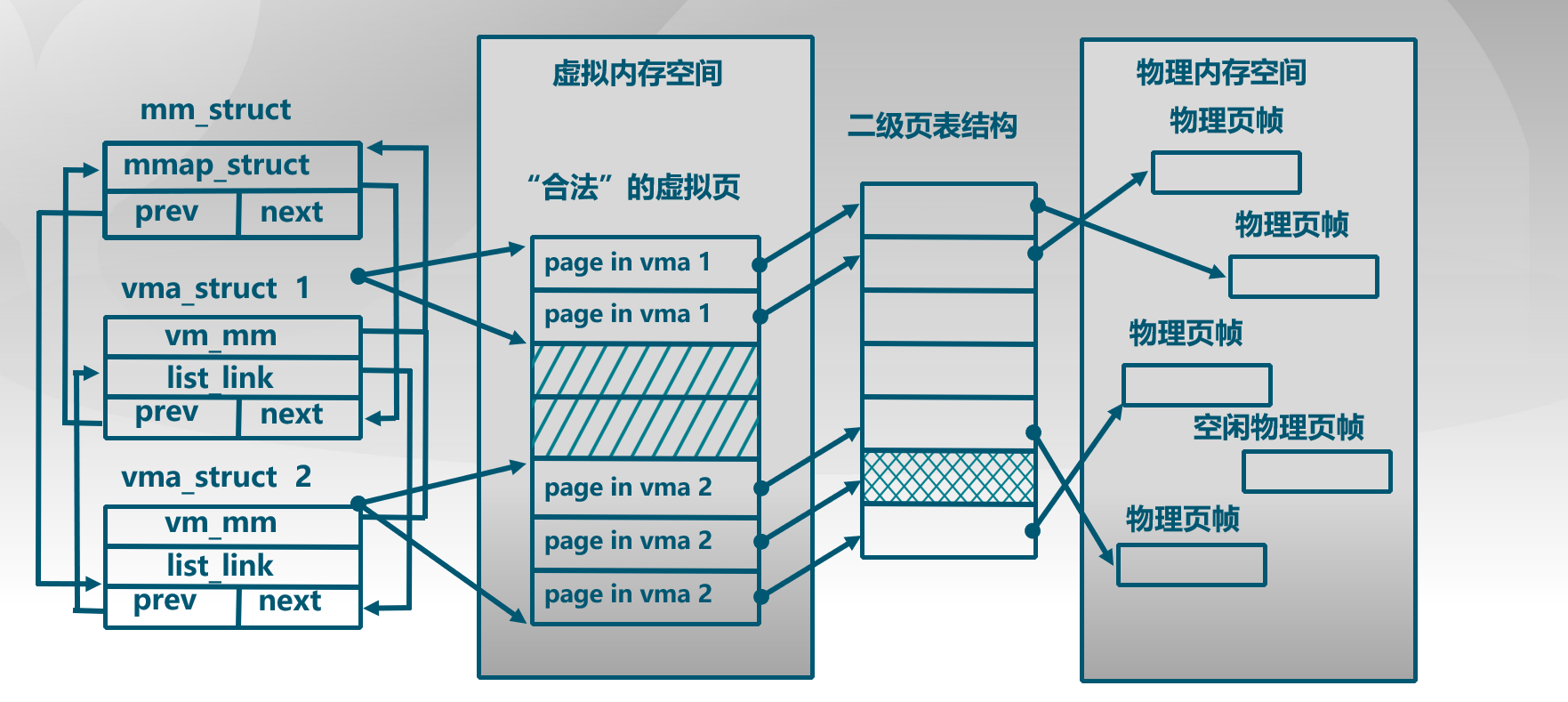
涉及vma_struct的操作主要为:
1 | struct vma_struct * vma_create(uintptr_t vm_start, uintptr_t vm_end, uint32_t vm_flags) |
根据输入参数vm_start,vm_end,vm_flags来创建并描述一个虚拟内存空间的vma_struct结构。
1 | void insert_vma_struct(struct mm_struct *mm, struct vma_struct *vma) |
把一个vma变量按照从小到大的顺序插入到所属的mm结构体的mmap_list链表中。
1 | struct vma_struct * find_vma(struct mm_struct *mm, uintptr_t addr) |
根据输入参数addr和mm,查找在mm变量中包含该addr的vma,即满足vma->vm_start<=addr<=vma->vm_end。
涉及mm_struct的操作主要为:
1 | struct mm_struct * mm_create(void) |
在mm_create中用kmalloc分配一块用于mm_struct的空间并初始化,而mm_destroy是mm_create的逆过程,释放对应的空间。
page fault异常处理
完成do_pgfault(kern/mm/vmm.c)函数,给未被映射的地址映射上物理页。设置访问权限的时候需要参考页面所在VMA 的权限,同时需要注意映射物理页时需要操作内存控制结构所指定的页表,而不是内核的页表。
1 | ptep = get_pte(mm->pgdir,addr,1);//根据缺页地址查找对应pte,若对应页表不存在,则创建一个 //若pte对应的物理页不存在,则分配一物理页并建立物理地址与逻辑地址的映射关系 |
do_pgfault函数在缺页的时候被触发,表明用户访问的虚拟地址在物理内存中没有对应的映射,这种情况可能是非法访存,也有可能是合理访存。该函数先检查非法情况,即通过vma中的标志位判断。
页访问异常错误码有32位,位0为1表示对应物理页不存在;位1为1表示写异常(比如写了只读页);位2为1表示访问状态异常(比如用户程序访问了内核空间的数据)。
1 | switch (error_code & 3) { |
以上为异常情况。以上情况之一出现时,那么就会产生缺页异常。CPU会把产生异常的线性地址存储在CR2中,并把表示页访问异常类型的值(页访问异常错误码)保存在中断栈中。
CR2是页故障地址寄存器,保存最后一次出现页故障的全32位线性地址。CR2用于页异常时报告出错信息。当发生页访问异常时,处理器把引起页异常的地址保存在CR2中。操作系统中对应的中断服务例程可以检查CR2的内容,从而查出线性地址空间哪个页引起本次异常。
我们需要完成的部分是对合理访问内存的处理。合理访问内存又分为以下两种情况:
- 该页存在于swap分区中
- 第一次访问该页,仅在
vma_struct中存在对应区域,而没有写入页表,分配物理页
此外,我们再关注一下check_pgfault的实现,
1 | pde_t *pgdir = mm->pgdir = boot_pgdir; |
在启动阶段建立好了启动页目录表,并且建立了如下映射关系
1 | virt addr = linear addr = phy addr + 0xC0000000 |
程序在声明变量时会分配对应的内存并建立映射关系,若直接访问或读取之前声明过的变量则不会引发page fault。这里将初始指针指向0x100 ,0x100存在于第1个虚拟页中,在初始的映射关系中并没有相关的条目,所以在第一次访问时触发缺页异常,此后访问地址都在一页的范围内,不会再引发异常。另外,虚拟地址从 0xC0000000开始是启动阶段的映射,之后的访问会动态改变其中页表项,映射也将不再是单一的连续映射,访问虚拟内存地址空间的地址均可以,并不是只有0xC0000000以后的虚拟地址才为合法的地址。
1 | struct vma_struct *vma = vma_create(0, PTSIZE, VM_WRITE); |
设置从0开始的1024个虚拟页为合法地址空间,并插入到对应的mm_struct中。
请描述页目录项(Pag Director Entry)和页表(Page Table Entry)中组成部分对ucore实现页替换算法的潜在用处。
通过设置PTE中的标志位来查看缺页中断的原因,在扩展时钟算法中,则需要使用PTE中的Access位和Dirty位进行记录该页的历史访问情况。
- 页表项中的访问位用于页面置换算法,页面置换算法可能需要根据不同页面是否被访问,访问时间和访问频率等进行淘汰页面的选择。
- 页表项中修改位供换出页面使用,页面换出的时候,需要判断外存上的相应页面是否需要重写。如果内存中该页面在使用期间发生了修改,则相应的修改位被设置,用于换出的时候通知操作系统进行外存相应页面的修改。
- 页表项的状态位用于指示该页是否已经调入内存,供程序访问时使用,如果发现该页未调入内存,则产生缺页中断,由操作系统进行相应处理。
如果ucore的缺页服务例程在执行过程中访问内存,出现了页访问异常,请问硬件要做哪些事情?
这种情况一般不会发生,除非操作系统内核出现故障。对于x86的CPU,会保存现场,并进入double_fault异常而非缺页异常供操作系统开发人员捕捉错误并处理。对于Qemu来说,三次出现嵌套缺页异常的情况下模拟器就会出错退出。
页目录项和页表项的dirty bit是何时,由谁置1的?
在页面被修改时由硬件置1的。
页目录项和页表项的access bit是何时,由谁置1的?
在页面被访问时由硬件置1的。
页面置换机制
可以换出的页
一个基本的原则是:并非所有的物理页都可以交换出去的,只有映射到用户空间且被用户程序直接访问的页面才能被交换,而被内核直接使用的内核空间的页面不能被换出。操作系统是执行的关键代码,需要保证运行的高效性和实时性,如果在操作系统执行过程中,发生了缺页现象,则操作系统不得不等很长时间(硬盘的访问速度比内存的访问速度慢2~3个数量级),这将导致整个系统运行低效。不难想象,处理缺页过程所用到的内核代码或者数据如果被换出,整个内核都面临崩溃的危险。
虚存中的页与硬盘上扇区的关系
如果一个页被置换到了硬盘上,那操作系统如何简洁地来表示这种情况呢?在ucore的设计上,在PTE中描述这种情况:当一个PTE用来描述一般意义上的物理页时,显然它应该维护各种权限和映射关系,同时有PTE_P标记;但当它用来描述一个被置换出去的物理页时,它被用来维护该物理页与 swap 磁盘上扇区的映射关系,并且该 PTE 不应该由 MMU 将它解释成物理页映射(即没有 PTE_P 标记),与此同时对应的权限则交由 mm_struct 来维护,当访问位于该页的内存地址时,必然导致 page fault,然后ucore能够根据 PTE 描述的 swap 项将相应的物理页重新建立起来,并根据虚存所描述的权限重新设置好 PTE 使得内存访问能够继续正常进行。
swap_out中设置pte的操作如下:
1 | v=page->pra_vaddr; |
swap_in中访问pte的操作如下
1 | pte_t *ptep = get_pte(mm->pgdir, addr, 0); |
swapfs_read的定义为
1 | int swapfs_read(swap_entry_t entry, struct Page *page) |
此时ptep指向的内容为swap_entry_t类型
1 | swap_entry_t |
如果一个页(4KB/页)被置换到了硬盘某8个扇区(0.5KB/扇区),该PTE的最低位(present位)应该为0 (即 PTE_P 标记为空,表示虚实地址映射关系不存在,接下来的7位暂时保留,可以用作各种扩展;而原来用来表示页帧号的高24位地址,恰好可以用来表示此页在硬盘上的起始扇区的位置(其从第几个扇区开始)。为了在页表项中区别 0 和 swap 分区的映射,将 swap 分区的一个 page 空出来不用,也就是说一个高24位不为0,而最低位为0的PTE表示了一个放在硬盘上的页的起始扇区号。通过这种方式来映射磁盘扇区。
ucore用了第二个IDE硬盘作为交换区来保存被换出的扇区,262144/8=32768个页,即128MB的内存空间。
执行换入换出的时间
换入的时机
当ucore或应用程序访问地址所在的页不在内存时,就会产生page fault异常,之后调用do_pgfault函数,判断产生访问异常的地址属于check_mm_struct的合法虚拟地址空间,若保存在硬盘swap文件中(即对应的PTE的高24位不为0,而最低位为0),则是执行页换入的时机,将调用swap_in函数完成页面换入。
换出的时机
换出针对不同的策略有不同的时机。ucore目前大致有两种策略,即积极换出策略和消极换出策略。
- 积极换出策略是指操作系统周期性地(或在系统不忙的时候)主动把某些认为“不常用”的页换出到硬盘上,从而确保系统中总有一定数量的空闲页存在,这样当需要空闲页时,基本上能够及时满足需求
- 消极换出策略是指,只是当试图得到空闲页时,发现当前没有空闲的物理页可供分配,这时才开始查找“不常用”页面,并把一个或多个这样的页换出到硬盘上。
基于FIFO的页面替换算法
完成vmm.c中的do_pgfault函数,并且在实现FIFO算法的swap_fifo.c中完成map_swappable和swap_out_victim函数。
1 | static int |
lab3内容较少,将后面部分的trapframe context挪至此处。
trapframe和context的原理和区别
在ucore中,trapframe和context均出现在了线程的调度中。实际上,结构体trapframe用于切换优先级、页表目录等,而context则是用于轻量级的上下文切换。两者的区别在于context仅仅能够切换普通寄存器,而trapframe可以切换包括普通寄存器、段寄存器以及少量的控制寄存器。
1 | struct trapframe { |
trapframe中依次存储了:
- 目标寄存器
gs,fs,es,ds段寄存器tf_trapno,err用于储存中断信息eip,cs,eflags用于存储陷阱(trap)返回后的目的地址esp,ss在权限发生变化时,用于指示新的栈的位置
ucore有两处用到了trapframe,一是中断调用,而是进程切换,接下来分别分析二者的情况
中断调用中使用trapframe
trapframe在中断中,在前期负责中断信息的储存,后期负责中断的恢复。同时,trapframe结构体是位于栈中的,其生成和使用都是通过栈的push、pop命令实现的。
中断发生时,以下代码将信息压入栈中,与tf结构体中成员变量一一对应,之后调用trap(struct trapframe *tf)函数。
1 | .globl __alltraps |
中断处理结束后,将原来信息一一pop,从而恢复之前的执行状态。
1 | # pop the pushed stack pointer |
在调用call trap之后,有一句popl %esp,而后续恢复的信息完全是基于该%esp进行定位的,那么在中断处理内存中,如果我们强行修改%esp成为我们希望接下来运行的代码段的trap描述,那么经过__trapret代码恢复trapframe后,你就可以让程序跳转到任何你希望的地方。
在lab1的challenge中,我们通过以下设置trapframe来完成用户态到内核态的切换
1 | if (tf->tf_cs != KERNEL_CS) { |
其中((uint32_t *)tf - 1) 地址后存放了我们修改后的trapframe,即popl %esp恢复的%esp的值。
进程切换中使用context
context结构体定义如下,其中存储了所有用户寄存器的值。
1 | struct context { |
context结构体主要在switch_to 函数中用到,switch_to传入前后两个context的地址, switch_to(&(prev->context), &(next->context)) ,具体实现如下。
1 | switch_to: # switch_to(from, to) |
进程切换中使用trapframe
进程切换仅仅通过switch_to函数是不够的,switch_to仅仅保存、恢复了普通寄存器,无法实现优先级跳转、段寄存器修改等等。接下来的工作就需要借助trapframe了。
由于switch_to函数跳转后,将调到context.eip位置。而这个跳转我们没法完全实现进程切换,所以我们可以将其设置为一个触发二级跳转的函数的地址,即forkret的地址入口。
1 | proc->context.eip = (uintptr_t)forkret; |
forkret函数定义如下,将当前进程的trapframe作为参数传入来切换进程。
1 | static void |
forkrets的定义如下:
1 | .globl __trapret |
然后再次回到中断恢复部分的代码,而其中的逻辑也完全相同。最终,进程跳转到目标进程的入口,而该入口的地址,被存放在proc->tf中。切换后进程对应的trapframe在kernel_thread函数中设置,将调用函数入口fn被储存在了eip中。
1 | int |